Introduction
Are you in doubt about what would be the right option to run Kubernetes on AWS? In this blog post you will get the answer, I will show you a few differences between EKS Node Managed and EKS Fargate.
Containers are not a new concept in the IT world: they have been widely used in public cloud or on-premises. Most public cloud providers offer different approaches on how to implement the containers. Let’s talk about EKS on AWS. You may ask yourself what does EKS stand for?
EKS cluster is a container orchestration platform that consists of a set of virtual machines called worker nodes and is designed to manage the lifecycle of containerized applications. Control Manager of EKS manages the nodes and the pods in the cluster. A “pod” is a group of one or more application containers. This platform also provides availability, scaling, and reliability of the pods.
AWS supports 2 EKS models:
EKS Fargate. This model has been designed to give developers the possibility to concentrate only on their workload, pods configurations, and application logic, without worrying about the infrastructure management, availability, fault tolerance, scaling, and patching of host machines. Therefore the , control manager and worker nodes are managed by AWS.
EKS Node Managed. This model gives developers the freedom to manage not only the workload, but also the worker nodes. Worker nodes consist of a group of virtual machines. However, the control manager is always managed by AWS.
The following drawing shows a high-level difference between EKS Fargate and Node Managed.
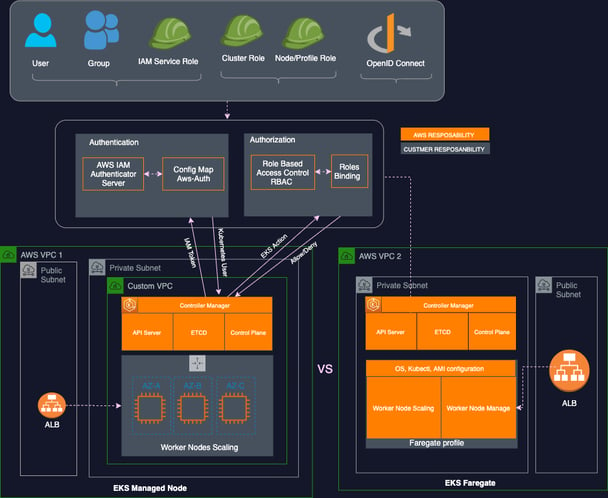
EKS Node Managed vs Fargate
Let me show you a few differences between them:
1. #SECURITY
Nowadays, security is a fundamental component. The importance of data protection increases as the amount of data grows, so it is important to have in place a good approach to protect the data and systems from challenging threats. A good way to start is by understanding the shared responsibility model: what are AWS’s and Customer’s responsibilities, and who is responsible to enhance the security of pods, network, incident response, and compliance. Both services are compliant by meeting the security standards, and there is also an SLA 99.99%.
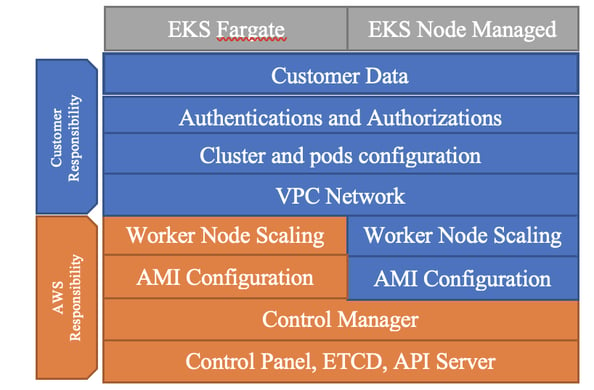
Shared responsibility EKS model
2. #SCALABILITY
Your resources increase or decrease according to the system’s workload demands. To better manage the workload, it’s good to have the right scaling strategy allowing systems to scale without interrupting their operation and to ensure that the activities work as it is expected.
There is a tool in AWS that helps you to manage different scaling approaches, this service is called Auto Scaling group(ASG). It provides vertical (scale-up) and horizontal scaling (scale-out). The scope of both these approaches is to deliver performance and capacity that the workloads require. But these models work differently. You may ask: Which one is a better solution? Let me briefly explain how they handle the resource based on the workload.
-2.png?width=485&height=442&name=pasted%20image%200%20(1)-2.png)
Scale-out vs scale-up
Scale-out: Add or remove nodes to the cluster, this means a group of virtual machines can be deployed as dependent pieces.
Scale-up: Add or remove capacity to a single node, you can add more CPU, RAM, Storage to this node. Not highly recommended as you don’t have a redundancy, and high availability, as this machine will reside in a single availability zone.
3. #NETWORK
Running the EKS cluster on AWS requires a pre-existing networking configuration. So, the first step is to set up the virtual private network (VPC) configuration. Keep in mind what workload you may have before deciding the Inter-domain routing (CIDR) of VPC. As your cluster grows and your applications become more complex you may need other resources running on the same network such as load balancers, databases, etc. It’s important to have a scalable solution that fits your requirements, so you won’t be in a position to recreate the resources and network from scratch because your CIDR block is too small in the first place. For both Node Managed and Fargate Control manager is part of the internal network managed by AWS, so you don’t have to worry about that. In the case of Fargate, AWS also manages the worked node network, so you’ll only need to calculate the pod IPs.
Let me give you two example of how many IP Addresses you need available to run a simple application in EKS. Here are some combinations of subnet size and machine type.
How many available IPs will we have for different Subnet CIDR range setup? In the illustration below are three different scenarios, and each one of them shows how many available IPs we will have for different SIDR ranges.
Subnet /25 = 126 IPs available
Subnet /24 = 254 IPs available
Subnet /21 = 2046 IPs available
Now let’s imagine we want to use different worker nodes types m5.large and m5.4.xlarge. Can we leverage all available IPs in both scenarios? As you can see in the illustration below there are some limitations on pods availability for different instance types.
M5 large = max 3 ENI and 9 Secondary IPs per ENI = max 27 pods available
M5.4 xlarge = max 8 ENI and 29 Secondary IPs per ENI = max 232 pods available
5 Node x 40 pods = 200 IPs address
30 Node x 40 pods x 2 cluster = 2400 IPs address
/24 can fit your requirement
You need at least /21 = 2046 IPs to setup cluster
In the example # 2 above, you will need at least CIDR /21 to fit the requirements.
4. #COSTS
Cost optimization is an important component in any organization, and it requires a good understanding of costs for short and long term. In AWS, you pay for computing capacity per second depending on what cluster you run. Let me show you how much Fargate and Managed Node will cost for one, three and six months. To illustrate this better, I will showcase you two different cases.
Managed Node Case: 15 nodes, using 2vCPU, 16 GB memory each (3 hours a day and 24 hours)
Managed Node EC2 Cost (15 nodes m5.large)
($0.0111/hour x 3 hours x 30 days) x 15 = $14.9/months
($0.0111/hour x 24 hours x 30 days) x 15 = $119.88//months
Fargate Case: 15 pods, using 2vCPU, 16 GB memory each (3 hours a day and 24 hours)
Total vCPU charges = # of Pods x # vCPUs x price per CPU-second x CPU duration per day (seconds) x # of days
15 pods x (2vCPU x $0.04048/(60x60) seconds) x 10800 seconds x 30 days = $109.29 /Month
15 pods x (2vCPU x 0.000011244) x 43200 seconds x 30 days = $437.16 /Month
Total memory charges = # of Pods x memory in GB x price per GB x memory duration per day (seconds) x # of days
15 pods x (8GB x $0.000001235) x 10800 seconds x 30 days = $48.0168 /Month
15 pods x (8GB x $0.000001235) x 43200 seconds x 30 days = $192.067 / Month
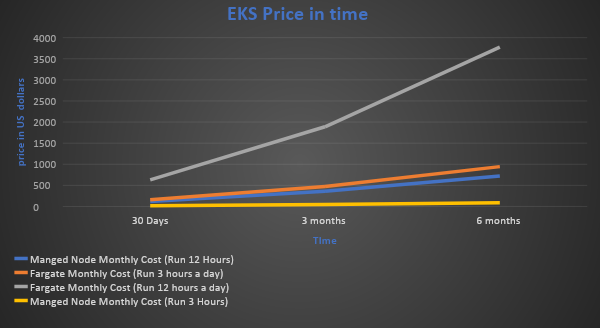
Short and long term costs
Conclusion
Customers may have complex container architecture in their data centers that may face challenges. However, taking advantage of the cloud gives you the flexibility to focus on what you need, and quickly solves scalability, readability, and security.



