Today, Artificial Intelligence (AI) is adding another dimension to improve the quality of life in different fields.
Let’s imagine a visually impaired person needs to read a label or a street sign but isn’t close enough to see it. Or what if an elderly person is at a restaurant and can’t read the menu or hear the waiter? What if you wanted to capture information from photos or slides and listen to the content later?
You can easily implement an AI application without needing too much experience as a data scientist.
In this article, I’ll create a small application which can be applied in the cases above. Plus, I will add a short video guide on how to implement this application.
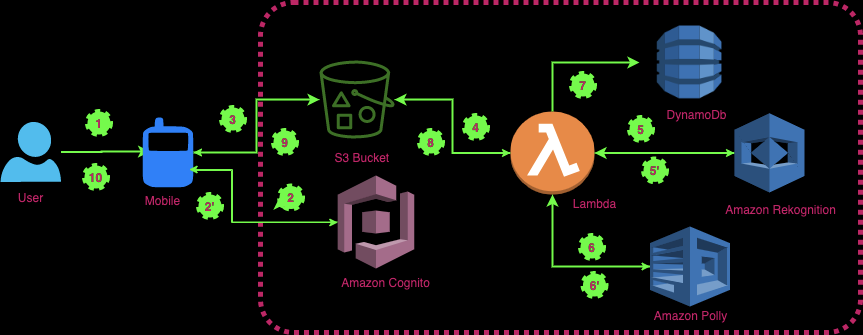
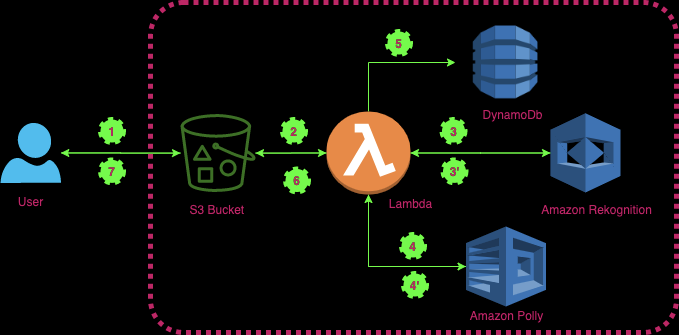
The diagram below explains how to extract the text from images and transform them into audio using AWS services.
Transform Text to Speech
Before we start, let me give an introduction to what these services are.
Amazon Rekognition is an AWS managed service based on deep learning technology that allows you to analyze photos and videos, recognize objects, concepts and scenes, and detects and extracts text in the images, among other features.
Amazon Polly is also based on deep learning technology, and allows you to transform the text into audio using various voices.
S3 is an object storage service that allows you to save static content such as images, etc.
DynamoDB is a NoSQL database service that is based on key-value and document data structures.
Lambda Function is a serverless compute service that runs your code in response to events.
Amazon Cognito provides a secure process of authenticating and authorizing users for mobile or web applications.
Let me explain how these services are integrated together step by step:
1. The user uploads the image in S3 bucket.
2. Once we have the image in S3 bucket, the bucket invokes the Lambda function and sends the image’s information in input to the Lambda function. Here is an example of a JSON file when S3 invokes a Lambda function.
{
"Records": [
{
"eventVersion": "2.1",
"eventTime": "2020-02-22T16:29:55.059Z",
"requestParameters": {
"sourceIPAddress": "127.0.0.1"
},
"s3": {
"configurationId": "test",
"object": {
"versionId": "dGkfynsSVHYbKDgSVJHIOrjRuzLb5M11"
"eTag": "10f98ebd80631b5fc05a581f3b4c8a96",
"sequencer": "005E5157045C9CE682",
"key": "beautiful-life-quotes-helen-keller-1531946634.jpg",
"size": 53881
},
"bucket": {
"arn": "arn:aws:s3:::extract-test-audio-zamira-demo",
"name": "extract-test-audio-zamira-demo",
}
}
},
"awsRegion": "eu-west-1",
"eventName": "ObjectCreated:Put",
"eventSource": "aws:s3"
}
]
}
Lambda function is the core of the serverless platform in AWS. This function refers to a number of executions of code that are happening at any given time. (from AWS documentation)
3. In the image below, the first execution of the Lambda invokes the detect_text api to detect the text from images. This function has three inputs (bucket, key, version), bucket is the bucket name when into which you’ve uploaded the images, key is the folder within the bucket, and the version is the object version. The function returns the test rekognition’s detect_text API finds in the image. This function in output return text.
Detect the Text Form Images
4. In the second execution, Lambda invokes synthesize_speech api. This is the api of Amazon Polly that allows you to transform the text into audio. This function has only one input(text), this input is coming from the previous function.

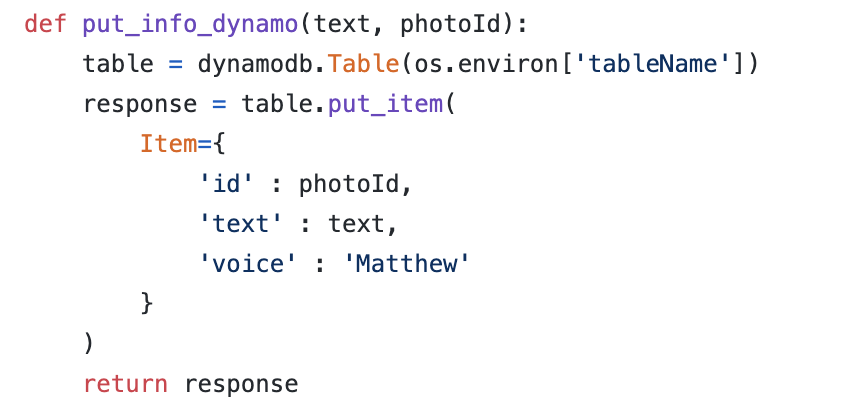
5. At the same time, data needs to be stored in DynamoDb, eg. the photo id and text that correspond to this particular photo.
6. The last process that Lambda executes is to store the generated audio in S3 via the s3 api, so it is ready to download by end-users.

This video is the tutorial on how you can build and implement this application step by step. You can also find the source code we use in the video in our code repository. You can also find the source code used in the video repository
Conclusion
As you can tell, it is so easy to integrate AI services in AWS. You can integrate as many services as you need, such as Amazon Cognito, Amazon Translate, and many others.
Imagine this: you are visiting another country and you don’t speak the language — I believe every one of you has been in this situation. This situation can go from difficult to easy in a matter of minutes. Take a picture with your phone, then your phone authenticates with Cognito and uploads the pictures into an S3 bucket. With this process, now you can recognize the object in the image, or detect the text in the image, and transform this text in audio, or translate the text in another language using another AI AWS service, Amazon Translate.
Using AI to connect the world is a great use case for this technology!